

Refonte d’architecture Data pour réduire le Time-to-Decision de 93% (48h à 3h)

Résumé
Contexte : Migration d'une architecture applicative vers une Modern Data Stack
Le client
Silvr est une Fintech française spécialisée dans le Revenue Based Financing (RBF) pour entreprises digitales (e-commerce et SaaS). L'activité repose sur l'analyse en temps réel de données financières et marketing pour l'octroi de financements.
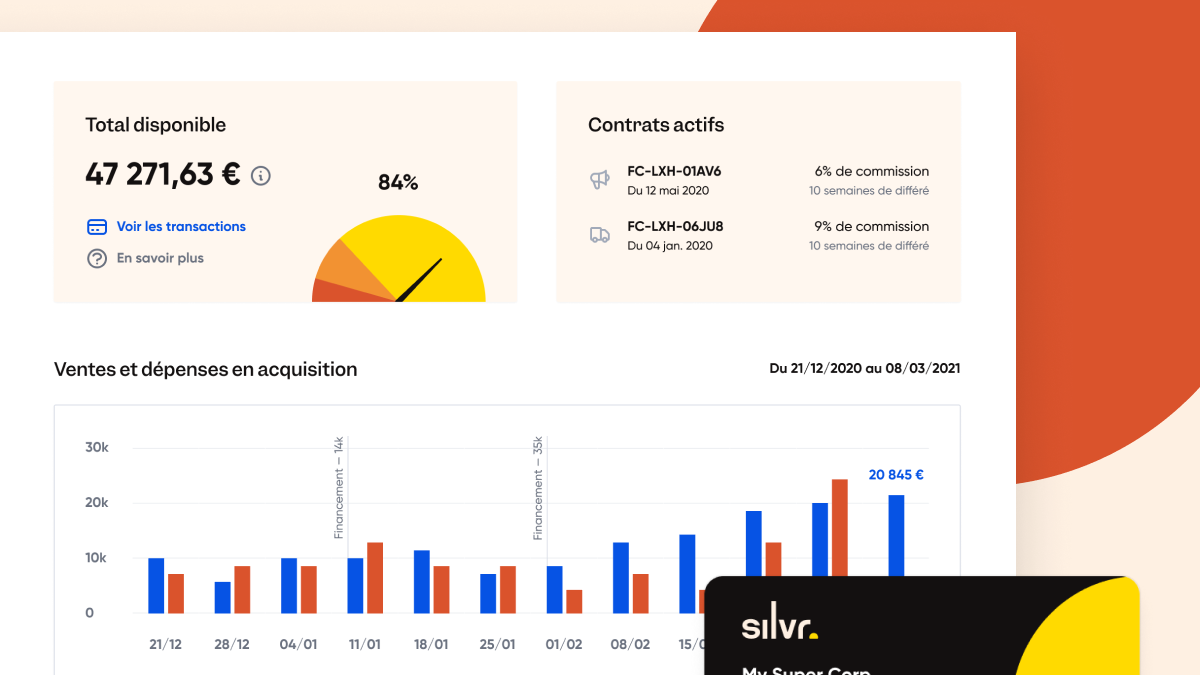
État initial de l'infrastructure
L'engagement contractuel de Silvr impose un délai de financement inférieur à 24 heures. Cet objectif nécessite l'ingestion, la consolidation et le scoring de volumes de données hétérogènes dans des contraintes temporelles strictes.
Points de blocage identifiés :
- Latence incompatible avec le SLA métier : 48 heures requises pour l'ingestion et la consolidation des données par dossier client, rendant impossible le respect du délai contractuel de 24h
- Architecture inadaptée : infrastructure conçue selon des patterns applicatifs (Software Engineering) plutôt que data-oriented (Data Engineering), générant des frictions structurelles sur l'accès et le traitement des données
- Absence d'autonomie des équipes métier : dépendance systématique aux équipes Engineering pour l'extraction de données et la génération de rapports
- Scalabilité limitée : difficulté à absorber la croissance des volumes de données sans refonte structurelle
Objectif technique
Réduire le délai de consolidation et de scoring d'un dossier client à moins de 3 heures, permettre l'autonomie des équipes métier dans l'accès aux données, et déployer une architecture scalable dimensionnée pour la croissance.
Solution : Refonte architecturale vers une Modern Data Stack
Approche : Standardisation et industrialisation de la plateforme data
Le projet vise le remplacement de scripts ad-hoc par une infrastructure data industrialisée, maintenable et extensible. La migration a été structurée en trois phases de 3 mois.
Phase 1 : Infrastructure & Data Engineering (Mois 1-3)
Déploiement de l'infrastructure data sur Google Cloud Platform (GCP).
- Orchestration : Déploiement d'Apache Airflow pour la gestion centralisée des workflows et le monitoring des pipelines
- Data Warehousing : Modélisation dans BigQuery avec architecture en couches (Raw / Staging / Marts)
- Data Engineering : Développement de pipelines d'ingestion Python, transformation via dbt, intégration CI/CD (GitHub Actions → BigQuery/dbt/Elementary)
- Connecteurs d'ingestion : Déploiement de DAGs Airflow pour les sources suivantes : Shopify, WooCommerce, Google Analytics, PrestaShop, Magento, Wix, PayPal, Facebook Ads, Stripe, API bancaires
- Transformation : Implémentation de modèles dbt avec tests de data quality intégrés
- Observabilité : Déploiement d'Elementary pour la surveillance de la qualité des données
Phase 2 : Self-Service Analytics & Gouvernance (Mois 4-6)
Mise en autonomie des équipes métier sur l'exploitation des données.
- Développement de dashboards Looker connectés au Data Warehouse
- Documentation des modèles de données et formation des équipes Operations et Finance sur l'exploitation en self-service
Phase 3 : Enrichissement métier (Mois 7-9)
Implémentation de logiques métier avancées (calculs de KPIs complexes, algorithmes de scoring) sur l'infrastructure stabilisée.
Stack technique déployée
- Orchestration : Apache Airflow
- Data Warehouse : Google BigQuery
- Transformation : dbt Core
- Data Integration : Airbyte
- Data Observability : Elementary
- Business Intelligence : Looker
Résultats mesurés
Performance des pipelines
- Latence end-to-end : Réduction de 93% du délai d'ingestion et transformation (48h → 3h)
- Respect du SLA : Le délai de financement (<24h) est désormais garanti par l'architecture data
Impact organisationnel
- Autonomie métier : Les équipes Finance, Marketing et Operations accèdent directement aux données via BigQuery et Looker, supprimant la dépendance aux équipes Engineering pour le reporting
- Automatisation : Les calculs de scoring sont entièrement automatisés, libérant les ressources techniques et analytics pour des initiatives à plus forte valeur ajoutée
- Scalabilité : L'architecture supporte une croissance significative des volumes de données sans refonte structurelle
Conclusion
La stabilisation des pipelines d'ingestion et de transformation constitue le prérequis technique pour toute initiative data avancée. Avec des données centralisées, fiables et à jour dans un Data Warehouse structuré, Silvr dispose des fondations nécessaires pour déployer des modèles de Machine Learning (scoring prédictif, détection de fraude) et évoluer de l'analytique descriptive vers l'analytique prescriptive. L'accès direct aux données via Looker a supprimé définitivement le goulot d'étranglement des équipes Engineering pour le reporting opérationnel, accélérant la prise de décision et permettant une allocation optimale des ressources techniques.

Découvrez d'autres cas clients


.jpg)
Construisons ensemble vos produits data
%20(1).webp)