

Le terme de Data platform est souvent au cœur des enjeux stratégiques des DSI. Pour autant, le concept de Data Platform ne date pas d’hier et les entreprises se sont toujours appuyées sur ces systèmes pour mettre en œuvre leurs projets Data.
Les avancées technologiques de ces dernières années ont permis l’apparition d’un nouveau type de Data Platforms : les Modern Data Platforms. Le concept reste le même, créer un outil central de gestion de la donnée au sein d’une entreprise, mais les moyens pour y arriver ont grandement changé.
Autrefois réservées aux entreprises à grands moyens financiers et humains et prenant la forme de lourds systèmes informatiques, les Data Platforms sont maintenant beaucoup plus accessibles financièrement et techniquement.
Définition d’une Modern Data Platform
Une Data Platform est un système central de gestion des données. C’est une solution utilisée pour traiter tout type de données durant tout leur cycle de vie, de leur collecte à leur restitution.
Les Data Platforms existent depuis toujours mais l'avènement récent de technologies telles que le cloud et l’IOT ont entraîné de grandes évolutions dans le domaine. Cela a notamment permis l’apparition des Modern Data Platforms, des Data Platforms construites autour des outils de la Modern Data Stack outils ayant pour caractéristiques d’utiliser des technologies cloud et d’être facilement utilisables et déployables.
Définition de la Modern Data Stack
La Modern Data Stack est un ensemble d'outils et de technologies, hébergés sur le cloud, ayant pour but de collecter, traiter, stocker et visualiser de la donnée.
Les outils de la Modern Data Stack peuvent être regroupés en différentes catégories, correspondant chacune à un aspect spécifique de la gestion des données. Il existe par exemple des outils en charge du retraitement des données ou d’autres permettant de créer un catalogue de données à partir d’une base. Chacun peut fonctionner de manière indépendante ou interagir avec les autres pour communiquer et échanger de la donnée.
Il existe une multitude de solutions pour chacun des blocs, permettant à chaque entreprise de se constituer sa propre combinaison, également appelée sa Data Stack.

Pourquoi est-elle “moderne” ?
En s’appuyant sur les perspectives offertes par le cloud, la Modern Data Stack propose une approche innovante. Elle permet à chacun de se défaire des contraintes de hardware (matériel et infrastructures physiques) et de faire face à des volumes de données variables avec des coûts calculés selon l’usage.
Son architecture décentralisée et modulaire (par bloc) permet une approche itérative et de facilement débuter des projets data sur des petits périmètres, en testant différents outils et en choisissant les plus adaptés aux contraintes établies. Cette flexibilité est aujourd’hui un atout recherché dans beaucoup d’entreprises.
En rendant la donnée accessible à tous grâce à des outils d’exploration ne nécessitant pas ou peu de compétences techniques, la Modern Data Stack permet une exploitation poussée de la donnée dans tous les domaines et d'outrepasser les barrières pouvant exister entre les équipes métier et les équipes techniques.
Quels sont les principaux composants d’une Modern Data Platform ?
Plus le volume de données et le nombre de projets data augmentent et plus les entreprises ont besoin d'une plateforme leur permettant de stocker, indexer et rechercher des informations dans de grands volumes de data, rapidement et facilement.
Les Modern Data Platforms répondent à ces exigences puisqu'elles permettent de stocker des données dans différents formats dans un datalake ou une base de données et fournissent une variété d'outils permettant d’exploiter ces données dans le but d’en extraire de la valeur ou des informations sous différents format, que ce soit grâce à du reporting ou de la prédiction.
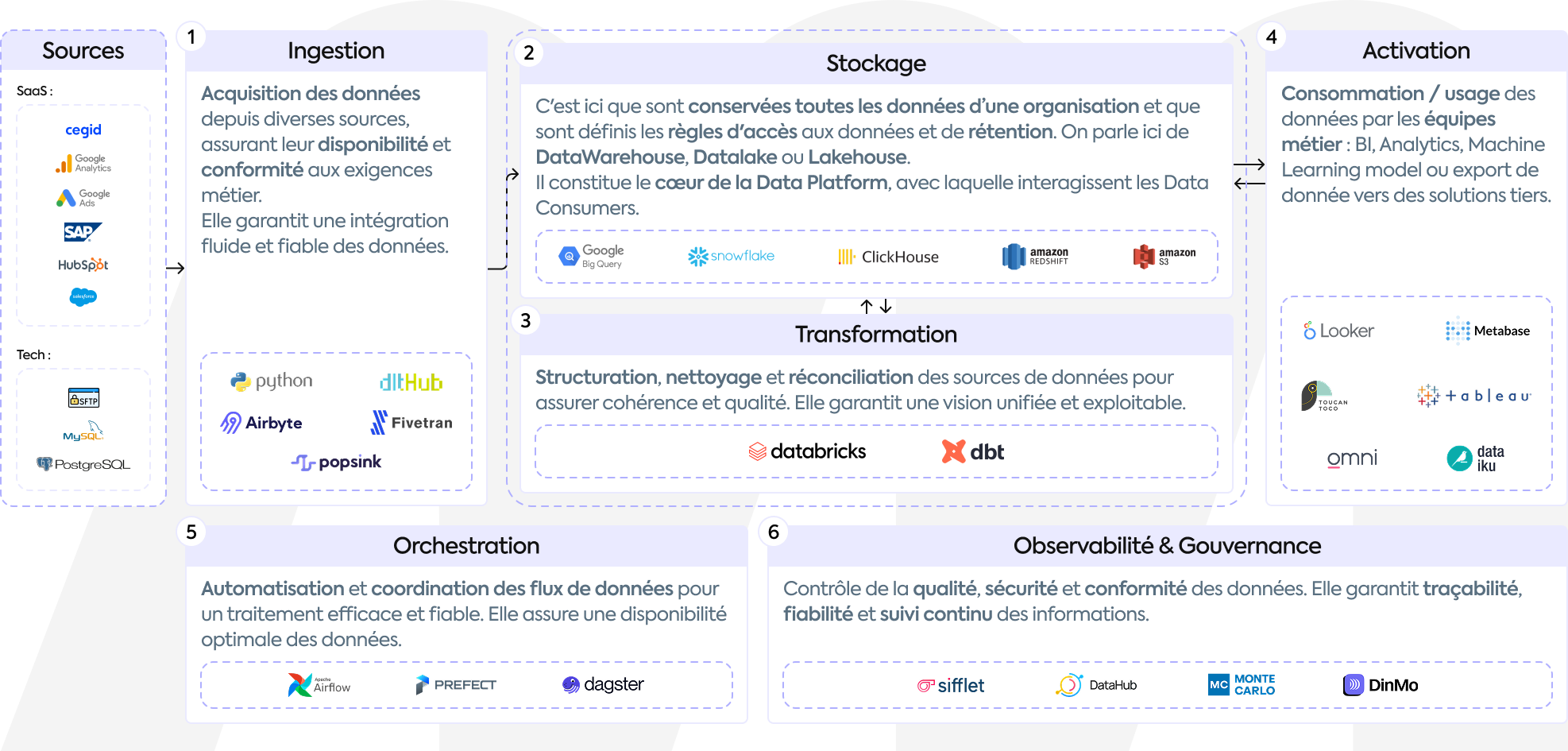
Ingestion des Données
Tout système informatique génère de la donnée, que ce soit un réseau social, un site de vente, un logiciel RH ou encore une solution de visualisation de données. Les données utiles à une entreprise existent dans des systèmes hétéroclites (CRM, ERP, API, applications Web, outils de paiement…) et dans des formats variés selon les sources. Pour pouvoir être exploitées et croisées entre elles, ces données sont collectées par la Modern Data Platform lors d’une étape appelée l’ingestion de données. Ces données sont à l'état brut, c’est-à-dire qu’elles n’ont subi aucune modification.
Des outils tels que Airbyte et Fivetran simplifient la collecte des données en fournissant un large éventail de connecteurs préconstruits pour transférer des données d’une source vers une destination.
Stockage des Données
Les données collectées sont acheminées et sauvegardées dans un espace de stockage avant d’être retraitées et exploitées. Cette étape est cruciale car elle est le cœur du système et doit pouvoir contenir et mettre à disposition de grands volumes de données rapidement et de manière fiable.Il existe différentes méthodes de stockage : les datawarehouses, les data lakes, les lakehouses… Les data warehouses contiennent de la donnée structurée dans un format défini au préalable. Ils sont utilisés pour stocker de grands volumes de données et pour explorer ces données à l’aide de requêtes SQL.
Les data lakes, quant à eux, peuvent contenir de la donnée non structurée au format variable et non défini au préalable, sous forme de fichier csv ou json par exemple, et sont utilisés pour stocker de la donnée en grande quantité.
Parmi les principales plateformes de data warehouse, nous retrouvons Google BigQuery, Amazon Redshift et Snowflake et pour les datalake il existe Amazon S3, Google Cloud Storage ou Azure Blob Storage.
Transformation des données et orchestration
Transformer les données signifie les nettoyer et les préparer pour de futures analyses. La donnée collectée depuis une source doit nécessairement être transformée pour qu’elle réponde à une question précise ou corresponde à un format attendu. Par exemple, pour analyser les ventes d’un hôtel sur différents canaux, il faut faire correspondre des données en provenance de son site Internet, d’AirBnb ou de Booking. Ces données, bien qu’elles contiennent la même information, ne sont pas présentées et structurées de la même façon et il est donc nécessaire de les retraiter pour obtenir une information uniforme de chiffre de ventes par canal et par jour.
Historiquement, les données étaient transformées avant d’être enregistrées en base. Cette approche, appelée ETL (Extract, Transform, Load), avait pour avantage de ne pas stocker de grandes quantités de données non utilisées et de ne conserver que de la donnée propre, uniformisée et formatée. Une nouvelle approche ELT (Extract, Load, Transform) a aujourd’hui largement dépassé l’ETL et propose de stocker l’intégralité des données collectées dans leur format brut avant de la retraiter. Cela permet d’assurer une traçabilité, un bon archivage et d’éviter des erreurs lors des transformations avant toute sauvegarde. Sa forte adoption est notamment due à la diminution des coûts de stockage au cours des dernières années. Les transformations peuvent être faites avec des solutions comme dbt ou Apache Spark.
Des séries d’étapes de traitement qui collectent, agrègent et formatent des données, également appelées pipelines de données, sont conçues pour déplacer les données de la source vers la destination. Ces pipelines sont planifiés et automatisés par un orchestrateur, comme Dagster ou Apache Airflow, qui gère les exécutions et les erreurs.
Data uses
Une fois que la donnée a été stockée et retraitée et que des indicateurs ont été modélisés, il est nécessaire de la rendre accessible et compréhensible. Une première exploitation peut se faire via du reporting et de la visualisation pour donner du sens à la data et la présenter sous un format facilement compréhensible. Les solutions BI sont des outils essentiels permettant aux équipes de suivre leur indicateurs clés et de prendre des décisions stratégiques éclairées.
Les Modern Data Platforms peuvent également intégrer des algorithmes de Machine Learning, permettant aux entreprises de construire des modèles prédictifs ou d’utiliser de l’Intelligence Artificielle. Dans des cas d'utilisation pratiques, cette fonctionnalité s'étend aux suggestions de contenu en temps réel sur les plateformes de e-commerce, améliorant l'expérience et l'engagement des utilisateurs en fournissant des recommandations personnalisées et pertinentes ou aux assistants avec lesquels les utilisateurs peuvent dialoguer et poser des questions relatives à la donnée, fondés sur de l’IA générationnelle.
Automation et Alerting
Un autre moyen d’exploiter les données et de leur donner de la valeur est de mettre en place des systèmes d’alerte et d’automatisation comme par exemple partager un récapitulatif des nouveaux inscrits sur son produit sur un canal Slack ou charger quotidiennement une liste de prospects répondant à certains critères dans Hubspot.
Data Gouvernance
Il est crucial pour une entreprise de garder le contrôle sur ses données et de savoir qui accède à quelle donnée. Bien sûr, à mesure que le volume de données et le nombre de consommateurs augmentent, il est de plus en plus difficile de garder la main et les risques de sécurité augmentent. Certaines solutions proposent des protocoles de sécurité robustes, des techniques de chiffrement et des contrôles d'accès pour protéger les données. Des outils tels que Privacera, Immuta et Okera sont des pionniers de la gouvernance, offrant des solutions avancées pour protéger les informations sensibles et maintenir l'intégrité des données.
Qui sont les utilisateurs d’une Modern Data Platform ?
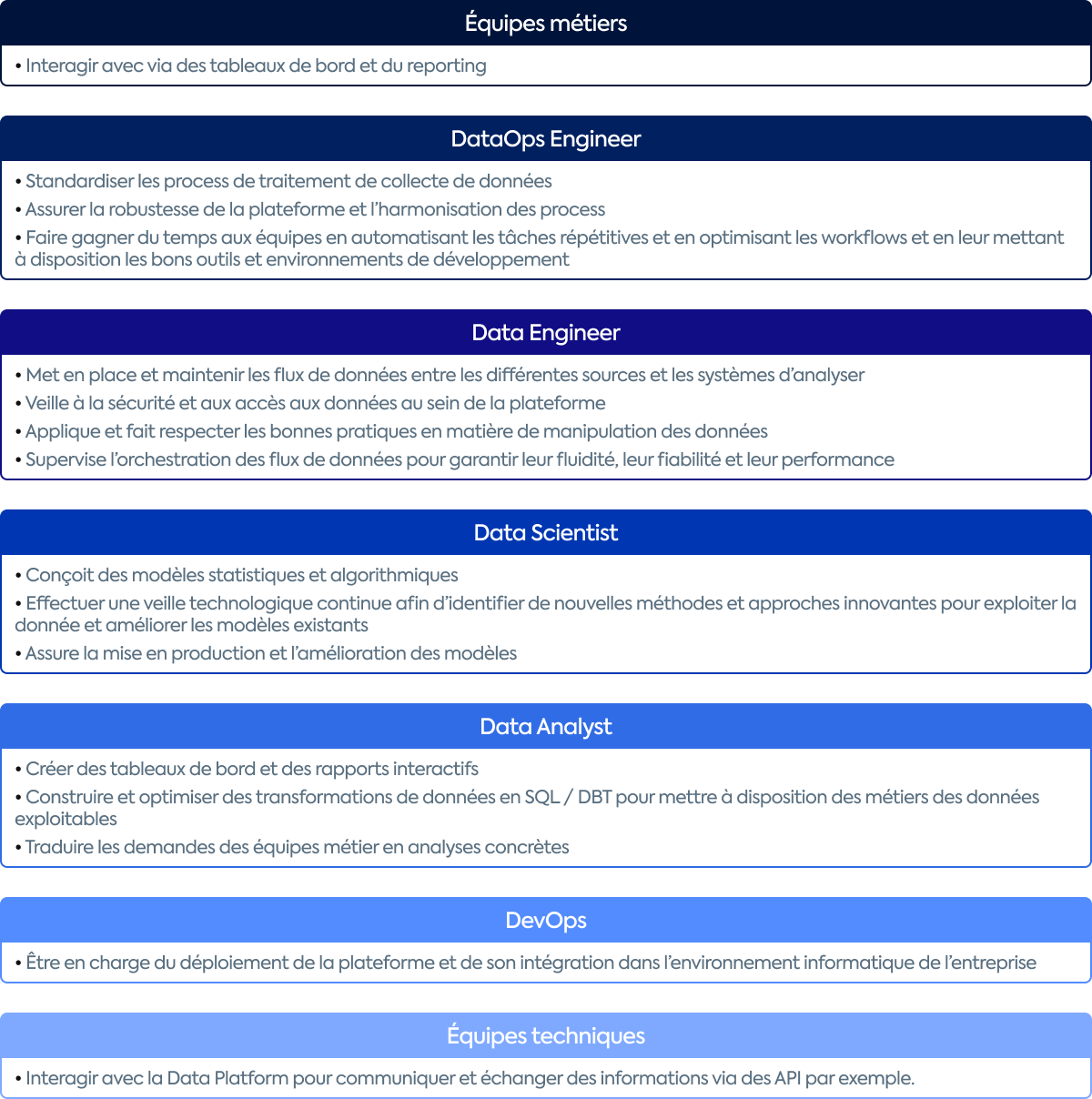
L’adoption de la donnée par les équipes métier est un important facteur de réussite d’un projet d'implémentation d’une Data Platform. Cette plateforme étant le centre de gestion de la donnée et la data étant au cœur du fonctionnement des entreprises data-driven, il est essentiel qu’elle soit une ressource commune et utilisée par tous.
.png)
Tous types de profils sont donc amenés à interagir avec la Modern Data Platform :
À quelles entreprises s'adressent les Modern Data Platforms ?
Toute entreprise disposant de données peut avoir besoin d’une Modern Data Platform pour lancer proprement et efficacement ses projets Data. Cela lui permettra alors de faciliter la collaboration entre ses équipes (métier ou techniques) et de disposer d’avantages concurrentiels lui permettant une meilleure compréhension de son fonctionnement et de ses actions.
Contrairement aux data stacks traditionnelles, la Modern Data Stack s’adresse également aux petites entreprises qui recherchent la flexibilité, l'efficacité et la scalabilité sans avoir d’importants moyens financiers à accorder. Alors que par le passé, seules les grandes entreprises pouvaient se permettre ces solutions, il est aujourd’hui possible d’en profiter pour une dizaine d’euros par mois.
Chez Modeo, nous sommes spécialisés dans la création de Modern Data Platform. Nous utilisons les outils de la Modern Data Stack pour accompagner les entreprises de toute taille dans la mise en place de leur stack data. Nous collaborons avec l’ensemble des équipes de nos clients pour choisir les bons outils, correspondants à leurs besoins et ainsi, permettre à chacun de bénéficier de la donnée et de sa valeur.
Nos ressources
• Pour aller plus loin : Le guide pour réussir l’implémentation de votre Modern Data Platform
• Demander via notre formulaire de contact, notre guide gratuit sur le Customer Data Platform &, IA (en partenariat avec Dinmo)
• Retrouvez une démo session de Samir Amellal, ancien CDO Auchan Retail, aujourd'hui DGA Tech chez France Travail et de Matthieu Rousseau, CEO de Modeo au Salon BIG DATA &, IA 2024

• Retrouvez ici le podcast sur la Modern Data Stack de notre CEO, Matthieu Rousseau, au micro de Robin Conquet pour l’émission DataGen.
.png)
Et pour nous contacter ou prendre un RDV avec un consultant Modeo, c'est ici !

%20(1).webp)